

1. 서 론
2. 재료 및 방법
2.1 공시재료
2.2 실험방법
3. 결과 및 고찰
3.1 ATR-IR spectra
3.2 주성분 분석
3.3 다차원 척도법
3.4 K-평균 군집분석
4. 결 론
1. 서 론
우리나라 전통한지의 주 섬유 원료는 비목질계 섬유인 닥나무 인피섬유이다. 인피섬유는 외수피부와 내수피부를 포함하는 형성층 사이의 식물 줄기에서 유래된 섬유이다.1,2) 특히, 닥나무 섬유는 목재 섬유에 비해 셀룰로오스 함량이 높고 리그닌 함량은 현저히 낮을 뿐 아니라 결정화도와 셀룰로오스 자체의 중합도가 높은 특징을 지녀 질기고 강인한 특성을 지닌다.3,4) 따라서 닥나무 섬유로 초지한 한지는 물리적 강도 특성과 내구성을 지녀 보존성이 우수하다.5,6) 전통한지로 제작된 기록 유산의 우수한 장기 보존 특성 역시 문헌을 통해 검증된 바 있다.7) 전통한지는 닥나무를 이용하여 우리나라 고유의 초지방식으로 제조된 종이를 일컫는데 이는 원재료, 초지방법, 도침의 유무, 생산지 등에 따라 다양하게 불리기도 한다.8)
한편 한지의 주원료인 닥나무 섬유의 경우 원산지의 기후 조건, 토양 조건 등과 같이 수종 및 산지에 따라 물리・화학적 특성에 이질성이 존재한다.9) 이러한 특성을 명시화 하기 위해 Cho 등10)은 국내 지역별 전통한지의 제조 공정 및 원산지에 따른 물리・광학적 특성을 비교하는 연구를 진행한 바 있다. 그러나 국가 중요 문화유산에 해당하는 지류 문화재 분석에 있어 보존과학 연구분야의 발전과 닥나무 섬유 수급에 대한 전문적 관리를 위해서는 비파괴 방식의 분석법이 보다 효과적일 것으로 사료된다. 최근 분광학적 분석과 같이 비파괴 분석법을 적용한 닥나무 인피섬유의 원산지 간 유연관계를 파악하는 분류학적 접근에 관한 연구가 다수 보고되고 있다.
목재 및 비목재 섬유의 비파괴 분류학적 접근을 위해 Schimleck 등11)은 Near infrared spectroscopy(NIR) 스펙트럼과 주성분분석(principal component analysis, PCA)을 이용하여 유칼립투스의 분류분석을 진행한 바 있으며 Kim 등12)은 Attenuated total reflection infrared spectroscopy(ATR-IR) 및 NIR 스펙트럼과 PCA를 이용하여 복사용지 및 국가별 전통지의 지종 분류 가능성을 연구하였다. 또한, Lee13) 등은 닥나무 인피섬유의 원산지 분류를 목적으로 ATR-IR 스펙트럼 응용 시 데이터 전처리가 기계학습 모델 성능에 미치는 영향을 평가한 바 있다. 이와 같이 분광 스펙트럼과 다변량 분석의 결합은 재료의 화학적 특성화를 위한 유용한 수단임이 다수의 연구를 통해 검증되었다.
다변량 분석 모델(multivariate analysis model)은 제품의 종류 및 원산지 판별, 진위 분석 등에 사용되며 이는 지도 학습(supervised learning)과 비지도 학습(unsupervised learning)으로 구분된다.14) 지도 학습은 독립변수에 대한 종속변수 값을 제공하여 학습시킨 후 학습된 답에 의해 반복적으로 결과 값을 예측하고 오차를 줄여가는 학습 방법이다. 반면, 비지도 학습은 답을 제공하지 않고 데이터 간 유사성과 상관관계를 찾아내어 상호 근접한 케이스를 동일한 집단으로 분류하는 알고리즘으로 지도 학습에 비해 계산 속도가 빠르며 다량의 데이터에서 군집을 발견하기 용이할 뿐 아니라 입력된 데이터만으로 기본 패턴을 찾을 수 있다는 이점이 있다.15,16) 비지도 학습은 데이터셋의 차원을 축소함으로써 데이터의 복잡성을 감소시켜주는 방법인 차원분석(dimension analysis)과 관측된 특성을 바탕으로 서로 유사한 특성을 지닌 케이스들을 동일한 집단으로 분류하는 방법인 군집분석(cluster analysis)으로 구분할 수 있다. 차원분석의 대표적 알고리즘에는 주성분 분석(principal component analysis, PCA)과 다차원 척도법(multidimensional scaling, MDS)이 있으며 군집분석의 대표적 알고리즘에는 K-평균 군집분석(K-means cluster analysis, KMCA)이 있다.17,18,19)
이에 본 연구에서는 전통한지의 주원료인 닥나무 인피섬유의 식별 및 판별을 위해 적외선 분광 스펙트럼 데이터를 수집하여 해당 데이터에 다변량 분석 기법의 비지도 학습 알고리즘을 접목하였을 때 증해 방법 및 원산지의 분광학적 이질성에 따른 분류분석 가능성을 확인하고자 하였다.
2. 재료 및 방법
2.1 공시재료
본 연구에서 사용된 원산지별 닥나무 인피 섬유에 대한 상세정보를 Table 1에 나타냈다. 각 닥나무 인피섬유는 증해 과정에 앞서 기요틴 커터로 절단하여 사용하였다.
Table 1.
Information on raw materials for manufacturing Hanji
| Sample | Origin | Status | Moisture content, % |
| W1 | Wonju | Inner bark | 5.01 |
| W2 | 4.10 | ||
| I1 | Imsil | 4.52 | |
| I2 | 4.78 | ||
| I3 | 5.06 | ||
| G1 | Goesan | 4.81 | |
| G2 | 5.80 |
2.2 실험방법
2.2.1 증해 방법에 따른 펄프 제조
본 연구에서는 지역별 닥나무 인피섬유의 증해를 위해 전건중량 30 g을 500 mL 삼각 플라스크에 넣어 오토클레이브(HST-506-6, Hanbaek, Korea)를 이용하여 Soda pulping, Soda-anthraquinone pulping, Organosolv pulping을 진행하였다. 각 증해 조건 별 알칼리 농도, 증해 온도, 반응시간 등 상세 정보를 각각 Tables 2, 3, 4에 나타냈다. 증해가 완료된 섬유는 200 mesh wire 상에서 세척 후 ATR-IR 측정을 위한 시료로 사용되었다.
Table 2.
Soda pulping conditions of paper-mulberry
|
Active alkali (%, as NaOH) |
Temperature (℃) | Time at max temp (min) |
Liquor- to-wood ratio |
| 10 | 120 | 90 | 8 : 1 |
Table 3.
Soda-anthraquinone pulping conditions of paper-mulberry
|
Anthraquinone (%) |
Active alkali (%, as NaOH) |
Temperature (℃) |
Time at max temp (min) |
Liquor- to-wood ratio |
| 0.1 | 20 | 120 | 120 | 8 : 1 |
Table 4.
Organosolv pulping conditions of paper-mulberry
|
Ethylene glycol (%) |
Catalyst (%, as sulfuric acid) |
Temperature (℃) |
Time at max temp (min) |
Liquor- to-wood ratio |
| 97 | 3 | 120 | 60 | 2 : 1 |
2.2.2 ATR-IR 측정
닥나무 인피섬유의 증해 방법과 원산지로 범주를 분류하여 비지도 학습 모델링을 시도하였으며 비교 분석을 위해 감쇠 전반사 적외선 분광기(Alpha-P model, Bruker Optics, Germany)를 사용하여 IR 스펙트럼 데이터를 수집하였다. 이때 측정 영역은 4000-400 cm-1 이었으며 4 cm-1의 단위로 측정하였다. 측정된 스펙트럼 데이터는 baseline correction과 vector normalization을 통해 보정하였으며 최종적으로 32회 스캔을 통해 수집된 데이터의 평균 값을 계산하여 스펙트럼을 나타냈다. 시료 별 스펙트럼 데이터는 각 10회 반복 측정하였다.
2.2.3 데이터 전 처리(Data pre-processing)
증해 방법 및 원산지에 따른 닥나무 인피섬유의 IR 스펙트럼 데이터를 보다 유용하게 분석하기 위해 ATR-IR 분석을 통해 얻어진 스펙트럼 데이터를 Savitzky-Golay 알고리즘에 의거하여20) 5차 다항식으로 2차 미분한 다음 R software(R Core Team, ver. 4.3.0, Auckland, New Zealand)를 이용하여 다변량 분석 모델을 생성하였다.
2.2.4 주성분 분석(PCA, principal component analysis)
PCA는 서로 상관관계가 있는 많은 변수를 상관관계가 없는 소수의 변수로 변환하는 차원축소 기법이며 유사 수종 인식 및 분류 분야에서 시각화 특성 분석을 위해 사용된다. 특히 PCA는 데이터의 분포를 넓게 하는 잠재적 공간(latent space)을 찾아 고차원 데이터의 손실을 최소화하여 효율적으로 축소하는 특징이 있다. Fig. 1은 PCA의 개념적 이해를 위해 시각화한 것이다.

2.2.5 다차원 척도법(MDS, multidimensional scaling)
MDS는 케이스간 변수를 측정한 후 이들간 거리를 기반으로 관계 구조를 2차원의 공간상에 시각적으로 표현하는 다변량 자료의 탐색적 분석기법이다. Eq. 1은 각 케이스간 유클리드 거리 행렬(euclidean distance matrix) 작성을 위한 수식을 나타낸 것이다. Eq. 1의 유클리드 거리는 모든 비교쌍에 대해 변수 값 간의 차이의 제곱을 합산한 후 제곱근을 구하여 거리를 측정하는 방법이다. 하지만 MDS에 의해 표현되는 score plot은 cluster의 변수와 관련된 논리적 근거를 제시하지 않아 PCA와 다르게 분류규칙에 대한 정보는 확인할 수 없다.
: Euclidean distance between cases i and j
: variable value (attribute value) in case i
: variable value (attribute value) in case j
: number of variables
2.2.6 K-평균 군집분석(KMCA, K-means cluster analysis)
KMCA는 데이터의 값을 통해 군집화(clustering)하는 기법으로 임의의 중심점(centroid)을 설정하여 이 중심점과 케이스 간의 거리를 기반으로 분류를 진행하여 군집을 형성시킨다. Fig. 2는 KMCA의 중심점 탐색 과정을 시각화한 것이다. Fig. 2에서 초기 중심점(initial centroid)의 위치에 따라 군집 형성 특성이 변화하는 것을 확인할 수 있다. 따라서 KMCA는 각 군집의 케이스간 평균을 계산하고 이를 새로운 군집 중심점으로 정해 케이스를 다시 분류함으로 더 이상 큰 변화가 없거나 설정된 최대 반복 횟수에 도달할 때까지 반복하여 군집을 최적화하는 작업이다. 또한, 해당 작업을 수행하는데 있어서 계산 시간이 짧아 대용량 데이터에 적합하다는 특징이 있다.

3. 결과 및 고찰
3.1 ATR-IR spectra
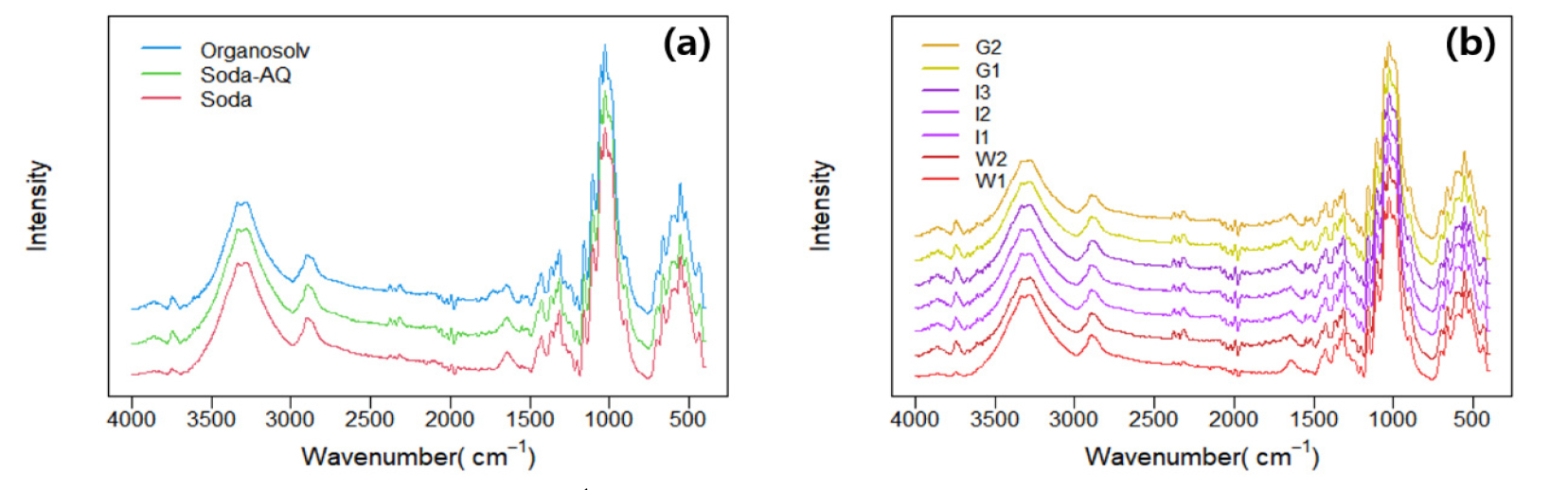
Fig. 3은 증해 방법과 원산지에 따른 닥나무 인피섬유의 원본 IR 스펙트럼을 나타낸 결과이다. 증해 방법에 의한 분류 및 원산지에 따른 분류에 앞서 해당 범주 이외의 변수들을 통제할 필요가 있다고 판단하였다. 따라서 닥나무 인피섬유의 증해 방법에 따른 IR 스펙트럼 데이터 비교 및 분류 분석은 W1 sample을, 원산지 별 범주의 경우 Soda pulping된 시료들을 기준하여 분석을 진행하였다. 스펙트럼 분석 결과 닥나무 인피섬유 자체의 셀룰로오스 및 헤미셀룰로오스에 기인한 화학 조성분이 발견되었으며 특징적인 흡수 피크로는 3415 cm-1(carbohydrates, O-H stretching), 2800 cm-1(carbohydrates, C-H stretching), 1422 cm-1(carbohydrates, CH2 bending), 1336 cm-1(carbohydrates, O-H in plane bending), 1055 cm-1(carbohydrate, C3-OH stretching)이 검출되었다. 21,22,23,24) 다변량 분석에 앞서 전처리 작업으로 Fig. 3의 raw IR spectra를 Savitzky-Golay 알고리즘에 의거하여 5차 다항식으로 2차 미분을 진행하였으며 그 결과를 Fig. 4에 도시하였다. 전 처리를 거친 스펙트럼에서는 원본 스펙트럼에서 검출한 흡수 피크 외에 1641 cm-1 (carbohydrates, O-H bending), 1335 cm-1(amorphous cellulose) 피크22,24)등이 추가적으로 검출되었다.

3.2 주성분 분석
1800-800 cm-1 영역은 cellulose fingerprint 등 목재 구성요소의 주요 작용기가 밀집 되어있는 영역이기에 목재 성분의 분자 구조 변화에 있어 유효한 특성화 피크가 다수 관찰되는 영역으로 알려져 있다.25,26) 따라서 본 연구에서는 스펙트럼 영역을 1800-800 cm-1로 축소하여 비지도 학습 알고리즘의 적용을 시도하였다. 스펙트럼 영역의 선택적 이용을 통한 입력 변수(input variable) 최소화에 대해 Hwang 등27)의 선행연구를 참조하였을 때 스펙트럼 영역을 4000-400 cm-1과 1800-1200 cm-1로 구분하여 학습 모델을 형성한 결과 불필요한 정보 및 노이즈가 제거되어 한지의 분류 모델 성능을 향상시킬 수 있는 것으로 확인되었다.
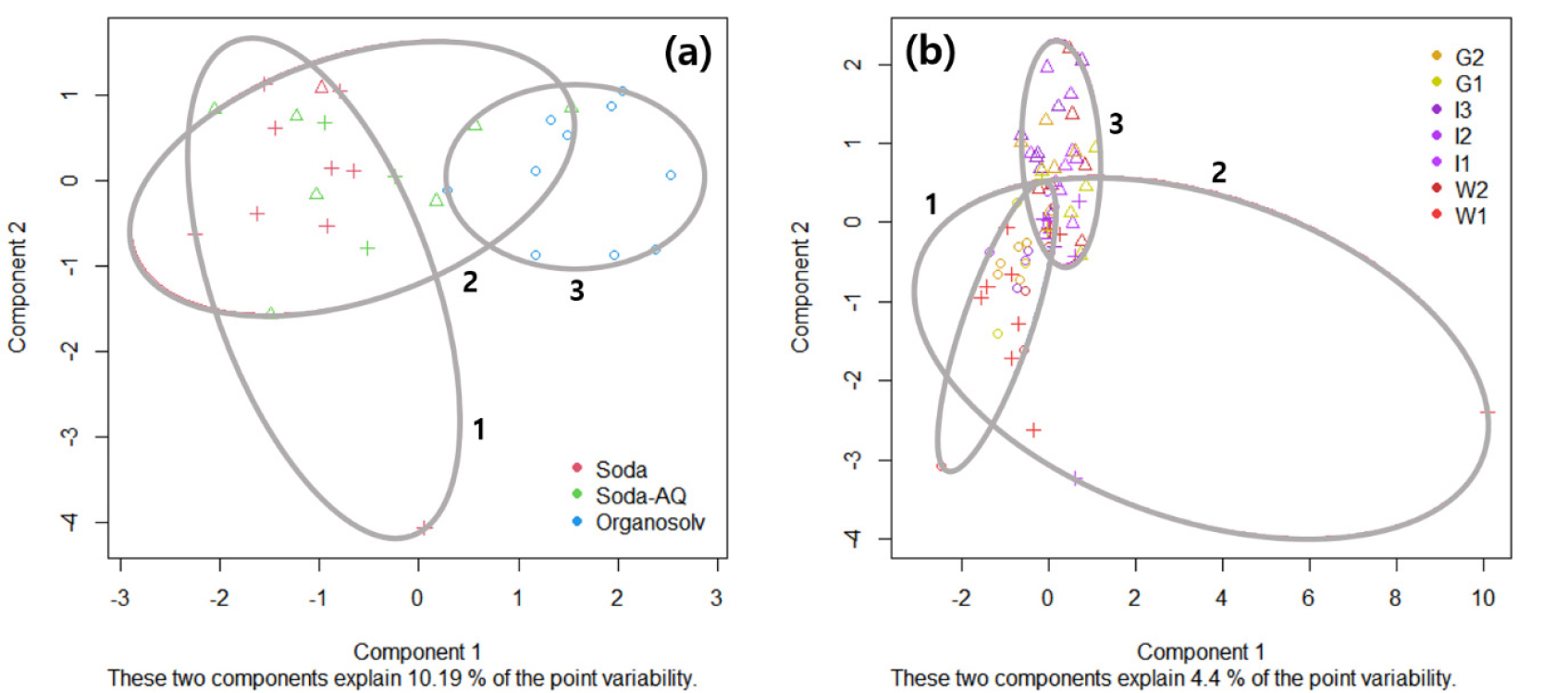
PCA는 높은 분류 특성을 보이는 주성분(PC)의 수를 지정할 수 있으며 본 연구에서는 각 주성분의 분산 기여도(proportion of variance)에 의거하여 증해 방법에 따른 분류는 PC1과 PC2를 이용하였으며 원산지에 따른 분류는 PC1과 PC5를 이용하였다. Fig. 5는 2nd derivative IR spectra를 통해 얻은 PCA score plot을 나타낸 것이다. 증해 조건에 기반한 모델 형성 결과(Fig. 5(a)) Organosolv pulping 조건의 cluster가 분류되어 형성된 것을 확인할 수 있었다. Fig. 6은 Fig. 4(a)의 1800-800 cm-1 파장영역과 PCA loading vector를 나타낸 것이다. Cluster 형성에 영향을 미치는 주요 성분의 분석을 위해 Fig. 5(a) score plot 상의 결과를 기반으로 PC1과 PC2에 대응하는 피크를 선별하여 Fig. 6에 표시하였으며 Table 5에 요약하였다.

Table 5.
Assignments with wavenumber on each principal component

PC1의 경우 1258 cm-1(sulfuric acid, S=O stretching vibration), 1045 cm-1(sulfuric acid, S=O stretching vibration), 811 cm-1(sulfuric acid, C-O-S bonds)등의 파장영역에서 피크가 발견되었으며 이는 Organosolv pulping 약품인 H2SO4 성분에 기인한 것으로 확인되었다.28,29) 반면, PC2의 경우 1635 cm-1(carbohydrates, O-H bending), 1422 cm-1(carbohydrates, CH2 bending), 1336 cm-1(carbohydrates, O-H in plane bending)등의 파장영역에서 피크가 발견되었으며 이는 섬유 자체 성분에 기인한 것으로 확인되었다.22,30)따라서 PCA score plot 형성 결과 PC2에 의한 분류는 확인할 수 없었지만 PC1에 해당하는 IR 피크는 Organosolv pulping 약품인 H2SO4에 의거하여 좌측에서 우측으로 cluster 형성에 관여하였을 것으로 판단된다.
반면 원산지에 기반한 모델 형성 결과(Fig. 5(b)) W1 sample의 경우 선분류 되었으나 그 외 sample간에는 각 성분의 상대적으로 적은 분산 기여도로 인하여 분류 특성이 현저히 감소하는 것으로 확인되었다. 상기 결과로 비추어 보아 화학적 조성이 거의 유사한 국내 닥나무 인피섬유의 경우 원산지에 의거한 적외선 분광분석 스펙트럼 데이터 기반 분류 모델 형성이 비효과적일 것으로 판단된다. 따라서 국내산 닥나무 인피섬유의 증해 시 사용되는 화학 약품의 대별성이 없는 경우 원산지에 따른 화학적 이질성을 다변량 분석 기법으로 구별하기에는 다소 무리가 있을 것으로 판단된다.
3.3 다차원 척도법
Fig. 7은 2nd derivative IR spectra를 통해 분석한 MDS score plot을 나타낸 것이다. 증해 조건에 기반한 모델 형성 결과(Fig. 7(a)) Organosolv pulping 조건의 케이스 간 거리기반의 분류가 이루어져 2차원에서의 cluster 형성이 이루어진 것을 확인할 수 있었다. 반면, 원산지에 기반한 모델 형성 결과(Fig. 7(b)) W1 sample을 제외한 다른 케이스 간 유클리드 거리에 뚜렷한 차이를 발견할 수 없었다. 이에 거리 기반의 분류 또한 증해 공정에 기인하지 않은 분류에는 다소 무리가 있을 것으로 판단된다.

상기 언급하였듯이 다차원 척도법으로 생성한 모델은 개체들의 군집화 성향만 확인할 수 있을 뿐, 군집들의 특징을 파악하거나 범주 수준들 사이의 연관성을 파악하기에는 어려움이 있어 해석 상 한계점이 존재한다.31) 본 한계점 극복을 위해 Shin 등31)은 개체군집들의 좌표점 크기를 응용한 변수들의 결합확률분포 탐색의 가능성과 좌표점의 위치를 통한 개체들의 군집화 성향을 탐색할 수 있다고 보고하였다. 따라서, 생성된 분류모델의 분석력 향상을 위해 좌표점 크기와 위치를 응용하여 변수들 사이의 연관성 탐색이 수행된다면 단순 분류가 아닌 논리적 규칙에 의거한 분류모델 형성에 대한 분석이 가능할 것이라 사료된다.
3.4 K-평균 군집분석
KMCA는 모델 생성을 위해 사전에 형성하고자 하는 cluster의 개수를 우선 지정해야 하는 특징이 있다. Cluster의 개수 지정을 위해 증해 방법 및 원산지에 따른 2nd derivative IR spectra의 최적 cluster의 개수를 각각 탐색하였다. 또한 주성분분석을 이용하여 기존 변수들을 2차원으로 축소한 후 2차원 상에 각 케이스를 나타내어 케이스 주변에 군집을 형성하도록 하였다. Fig. 8은 두 모델 형성의 최적 cluster 결과인 K=3을 각각 입력시켜 얻은 KMCA score plot을 나타낸 것이다. 증해 조건에 기반한 모델 형성 결과(Fig. 8(a)) 앞선 Organosolv pulping cluster(3)는 분류가 이루어졌으나 Soda pulping cluster(1)와 Soda-AQ pulping cluster(2)의 경우 분류가 이루어지지 않았다. 관측 값의 교집합 형성 정도를 파악하기 위해 kmeans function을 이용하여 cluster 크기를 탐색한 결과 cluster(1)=12, cluster(2)=8, cluster (3)=10의 결과 값이 할당되었다. 즉, Soda-AQ pulping의 관측 값 일부가 이탈하여 Soda pulping cluster(1)에 할당된 것을 확인할 수 있었다. 원산지에 기반한 모델 형성의 경우 앞선 모델들과 마찬가지로 분류 정도가 불량하였다. 분류 모델 성능 향상을 위해 Lee 등16)과 Kang 등17) 은 선택적 스펙트럼 데이터(1800-1200 cm-1) 입력 및 전처리 방법이 기계학습 모델링에 있어 미치는 영향을 평가하였으며 입력변수와 데이터 전처리 방법에 따라 최종 모델 형성 시 분류 정확도에 영향을 미칠 수 있다고 보고하였다. 따라서 본 연구에서 분류가 명확하게 이루어지지 않은 모델의 경우 본 연구에서 설정한 스펙트럼 영역(1800-800 cm-1)보다 더 제한한 입력 변수의 선택적 축소 혹은 스펙트럼 데이터의 전처리 방법에 따른 분류 모델의 성능 향상이 필요할 것으로 사료된다.
4. 결 론
본 연구에서는 화학적 성상에 따른 닥나무 인피섬유의 식별법으로서 적외선 분광분석 스펙트럼 데이터와 다변량 분석법 중 비지도 학습법의 결합을 시도하였다. 상기의 목적 달성을 위해 닥나무 인피섬유 시료군을 증해 방법 및 원산지 별 클래스로 범주화 하였다. 분류를 위한 비지도 학습 알고리즘은 PCA, MDS, KMCA로 설정하였다. 연구 결과 증해 공정 상 사용되는 화학 약품의 차별성이 있는 경우 증해 약품에 의거한 분류 가능성을 일부 확인할 수 있었다. 증해 방법에 따른 범주에 한하여 분류 모델 별 특성으로는 PCA의 경우 분류에 영향을 미치는 화학적 작용기를 추출하고 이를 근거한 cluster 형성 특징을 일부 관찰할 수 있었다. MDS와 KMCA의 경우 역시 각 케이스 간 유클리드 거리에 기반한 분류가 일부 가능한 것으로 확인되었다. 그러나 원산지 범주에서의 각 분류 모델은 각 성분의 낮은 분산 기여도로 인하여 명확한 cluster 형성이 불가하였다. 따라서 적외선 분광분석 스펙트럼 데이터와 비지도 학습 기반의 분류 모델의 적용은 국내 닥나무 인피섬유 원산지 식별을 위한 절대적 모델로의 적용은 불가할 것으로 사료된다. 그러나 첨가제 혹은 증해 방법 차이에 기인한 화학적 이질성 탐색을 위한 수단으로서는 일부 활용가치가 존재할 것으로 사료된다. 향후 보다 우수한 분류 모델의 생성과 분류에 대한 논리적 근거 확보를 위해 선택적 축소를 통한 노이즈 제거, 스펙트럼 전처리 방법의 다양화 및 비선형 분류 모델의 적용 등의 방법이 검토될 필요가 있다고 사료된다.
